Optical character recognition, or OCR, is a key tool for people who want to build or collect text data. OCR uses machine learning to extract words and lines of text from scans and images, which can then be used to perform quantitative text analysis or natural language processing. Here at the Urban Institute, we’ve used OCR for tasks such as automated text extraction of hundreds of state zoning codes and maps and the collection of text from nonprofit Form 990 annual reports.
A plethora of OCR services exist, but we didn’t know which were the most accurate for Urban projects. OCR services can vary by cost, ease of use, confidentiality, and ability to handle other types of data, such as text appearing in tables or forms, so accuracy is just one dimension to consider. Although we haven’t tested every OCR service, we chose four representative examples that vary across these dimensions. Below, we provide a thorough comparison, as well as the code to replicate our accuracy competition yourself:
1. Amazon Web Services (AWS) Textract, which is fully integrated with other AWS cloud-computing offerings
2. ExtractTable, a cloud-based option that specializes in tabular data
3. Tesseract, a long-standing, open-source option sponsored by Google
4. Adobe Acrobat DC, a popular desktop app for viewing, managing, and editing PDFs
Accuracy
The best way to improve OCR accuracy is through data preprocessing. Enhancing scan resolution, rotating pages and images, and properly cropping scans are all methods to create high-quality document scans that most OCR offerings can handle. But practically speaking, many scans and images are askew, rotated, blurry, handwritten, or obscurely formatted, and data cleaning can be too time-consuming to be feasible. We wanted to test the four OCR candidates against the messiness of real-world OCR tasks, so we compared how each tool handled three poor-quality documents.




We converted all 12 pieces of output (4 OCR offerings x 3 documents) into text files for nontabular text and CSV files for tabular text, and we compared them against “ground truth” text, which was typed by a human.
For each document and OCR service, we computed a text similarity score using the Levenshtein distance, which calculates how many edits are necessary to change one sequence of text into another. Because common errors made by OCR software occur at the character level (such as mistaking an “r” for an “n”), this framework made sense for evaluating accuracy.
Extracted text is not always outputted in the same order across OCR offerings (especially in cases of multicolumn formatting, where some services may first read down one column and others may start by looking across the columns). This variability motivated us to use the token sort ratio developed by SeatGeek, which is agnostic of text order. Token sort splits a sequence of text into individual tokens, sorts them alphabetically, and then rejoins them together and calculates the Levenshtein distance as described above, meaning “cat in the hat” and “hat in the cat” would be considered a perfect match.
From our comparison, we found that Textract and ExtractTable lead the way, with Tesseract close behind and Adobe performing poorly. All four struggled with scan 3, which contained handwritten text, but the high performers handled askew and blurry documents without major issue.
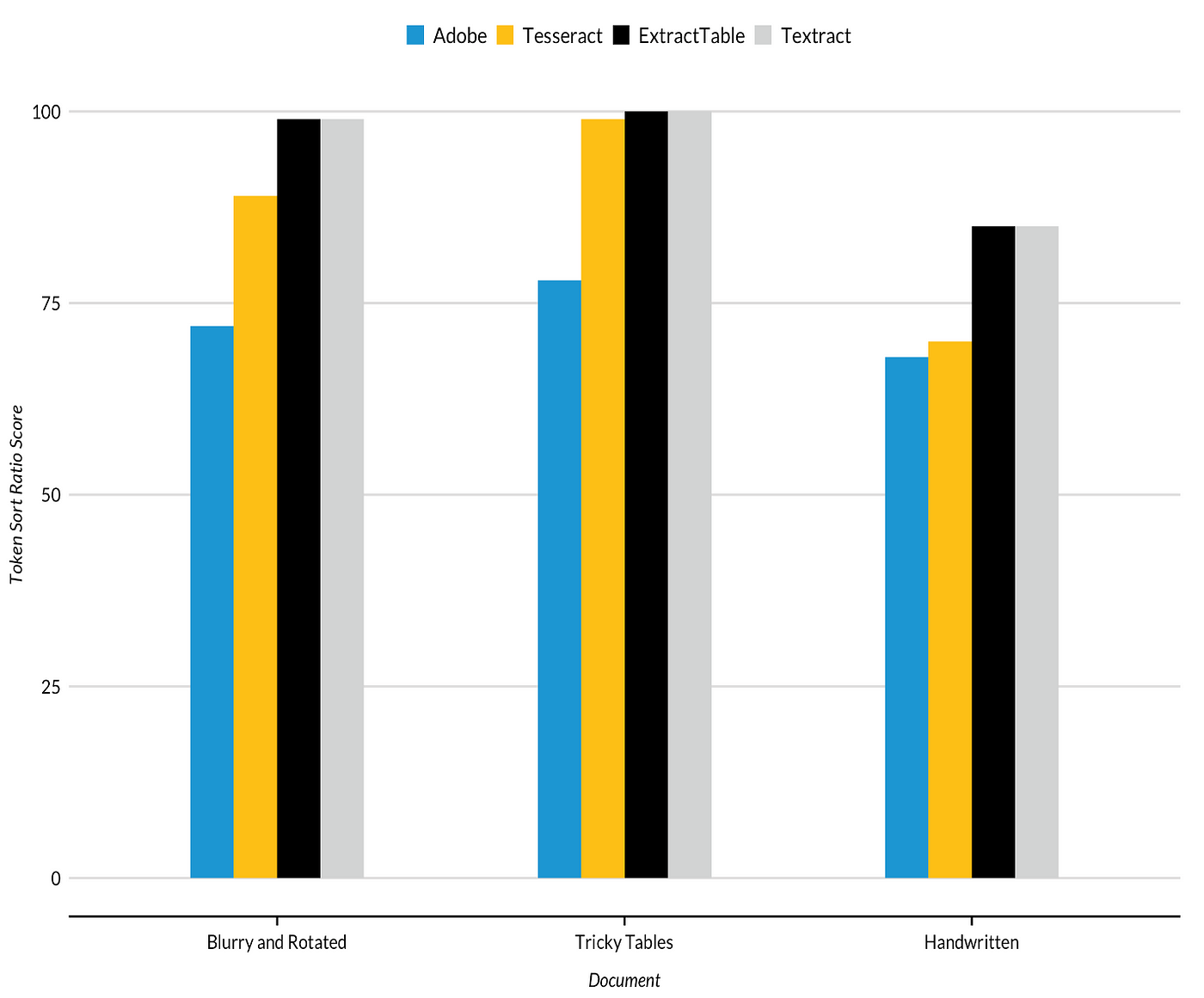
Cloud-Based OCR Offerings Outperformed Competitors across All Three Document Types
The scores from this “fuzzy matching” procedure generally indicate which OCR offering processed the most text correctly, but a single number can’t reliably tell the whole story. First, the scores are rounded to the nearest whole number, so there is some granularity lost in the comparison. Second, not all errors are created equally. If OCR software interprets the word “neighbor” as “nejghbor,” then token sort scoring will count one incorrect character, but the lexical understanding of that word is not greatly affected. But if the software mistakes “quality” for “duality,” that would totally change the meaning of the word yet yield a similar score.
These scores can serve as useful rules of thumb for OCR accuracy, but they are no substitute for a deeper dive into the output text itself. To allow for this deeper comparison, we published these results, including the original scans, all code, and outputs documents to this public GitHub repository.
We also include an Excel file with the tabular output from Textract and ExtractTable alongside benchmark tables for comparison. The table extraction performance looks comparable between the two services, except for a pair of rows that ExtractTable mistakenly merges. (ExtractTable’s Python library does include a function for making corrections to improperly merged cells to remedy this issue.)
Cost
Open-source options like Tesseract are the most cost-effective choice, but by how much depends on the size of the input and desired output (information from text, tables, and/or forms). AWS Textract charges $1.50 for every 1,000 pages, although it costs more to additionally extract text from tables ($15 per 1,000 pages), forms ($50 per 1,000 pages), or both ($65 per 1,000 pages). The user specifies up front which kinds of text to extract. ExtractTable users purchase credits up front (1 credit = 1 page) and pay on a sliding scale. The price per 1,000 pages to extract tabular data ranges from $26 to $40, and it costs slightly more to extract nontabular text (ranging from about $30 to $45 per 1,000 pages). For jobs that don’t require pulling key-value pairs from forms, Textract is the cheaper of the two cloud-based options, though ExtractTable uniquely offers refunds on bad and failed extractions. Finally, Adobe Acrobat DC requires an annual subscription that charges $14.99 per month (or a month-by-month plan costing $24.99 per month), which includes unlimited use of OCR and other PDF services.
Confidentiality
Although the documents in this competition all consist of nonsensitive text, natural language processing and quantitative text analysis can involve confidential data with personal identifiable information or trade secrets. ExtractTable explicitly guarantees that none of the data generated through purchased credits are saved on their servers, the gold standard here. AWS stores no personal information generated from Textract, though it does store the input and log files. Users can also opt out of having AWS use data stored on its servers to improve its AI services. Tesseract has no built-in confidentiality mechanism and depends entirely on the systems you use to integrate the open-source software.
Ease of use and output
Each OCR user will have a different use case in terms of the output required and a different level of comfort with code-based implementation, so ease of use is an important dimension for each of these offerings. For users looking for a no-code option, Adobe can perform OCR by simply right-clicking on the document in the desktop app. Although Adobe can process documents in batches, the output will be a searchable PDF, which is great for finding text within scanned documents but not for collecting data for text analysis. Converting the searchable PDF to text files is possible, but we find that some of the resulting text can be unintelligible.
We used the tesseract package in R, which provides R bindings for Tesseract. (A Python library is also available here.) Using tesseract is quite simple, and the output can be either a string of text (easily exported to a .txt file) or an R dataframe with one word per row. The creators of the tesseract package also recommend using the magick package in R first to preprocess images and enhance their quality. To keep the playing field level, we did not do that above, but it could lead to improved results for Tesseract users.
ExtractTable’s API and Python library similarly make it possible to process image files and PDFs in just a few lines of code, outputting tabular text in CSV files and nontabular text in text files. ExtractTable also has a Google Sheets plug-in.
The Textract API is less user-friendly, as it entails uploading documents to an Amazon S3 bucket before running a document analysis to extract text in nested JSON format. We use the boto3 package in Python to run the analysis and various pandas functions to wrangle the data into a workable format. Outputting tabular data in CSV format also requires a separate Python script.
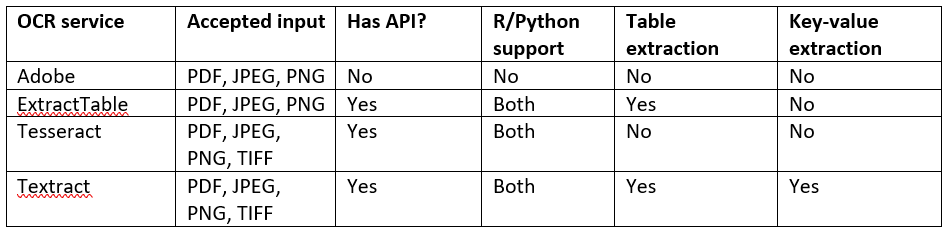
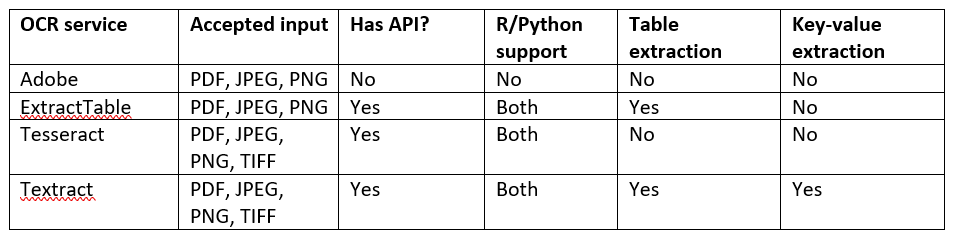
All offerings support PDF, JPEG, and PNG input, and Tesseract and Textract can handle TIFF files as well. Adobe will convert other image files to PDF before parsing text, but Tesseract will do the opposite, creating image files whenever the input document is a PDF before running OCR on the new file.
Lastly, if the use case involves extracting text from tables, both Textract and ExtractTable can parse the text and preserve the layout of tabular data. And Textract is the only one of the four options that supports extracting key-value pairs from documents such as forms or invoices.
Conclusions
Ultimately, the right OCR offering will depend on the use case. Adobe is an excellent tool for converting scans to easily searchable PDFs, but it probably doesn’t fit very well into a pipeline for batch text analysis. Tesseract is free and easy to use, and if high accuracy isn’t as important or your documents are high quality, then the open-source, low-hassle model may suit some users perfectly well.
Perhaps unsurprisingly, the paid, cloud-based offerings win the competition, and each offers certain advantages at the margins. Many downstream natural language processing tasks require cloud-computing infrastructure, so if your organization already uses a cloud service provider, offerings such as Textract can plug into existing pipelines and be quite cost-effective, especially at scale. On the other hand, ExtractTable may appeal to individual researchers for its impressive performance, low barrier to entry, and other unique benefits, such as confidentiality guarantees and refunds for bad output.
In part because Urban already uses AWS for our cloud computing, we found Textract best suited large batches of text extraction because of its low cost and integration with other AWS services. But for smaller operations, we found ExtractTable to be a sleeker, more user-friendly alternative that we also recommend to our researchers.